Duseok
May 5, 2020
SmartShuttle
SmartShuttle 논문의 동기와 주요 아이디어를 정리하기 위한 글이다. 디테일을 확인하고 싶으면 논문을 확인하자. 또한 이 글의 그림들은 모두 해당 논문에서 가져왔다.
정보
- 저자: Jianjun Li (Univ. of Chinese Academy of Sciences)
- 학회: DATE 18”
- 링크: https://ieeexplore.ieee.org/document/8342033
내용
Intro
기존의 CPU나 GPU에 비해 성능이나 에너지 효율이 좋은 NPU가 많이 제안되고 있다. 많은 연구들이 계산 방법을 최적화 하는 것에 집중하고 있는데, NPU의 에너지 소모는 오프 칩 메모리 접근이 더 큰 부분을 차지하고 있다. 예를 들어, DianNao [1]와 Cambricon-X [2]의 경우는 전체 에너지 소모량의 80%이상을 오프 칩 메모리 (대부분 DRAM) 를 접근하는데 소비한다. 따라서 오프 칩 메모리 접근을 줄이는 것이 에너지 효율을 높이는데 주요한 요소이다.
기존의 연구들은 한 타입의 데이터를 최대한 재사용한다 [3], [4]. 하지만 저자들의 실험에 따르면, 한 타입의 데이터만을 재사용하는 것은 다양한 모양의 convolution 레이어가 있는 딥 러닝 네트워크에서 오프 칩 메모리 접근을 줄이는데 한계가 있다. 즉, convolution 레이어의 인풋, 아웃풋, 커널 크기가 다르기 때문에 각각의 레이어마다 서로 다른 데이터 타입을 재사용해야한다고 주장한다.
따라서 이 논문은 Adaptive layer partitioning과 Scheduling scheme을 제안한다. 이 방법 자체를 SmartShuttle이라고 부른다. 또한 데이터 재사용과 Sparsity가 오프 칩 메모리 접근에 끼치는 영향을 분석하였다 (레이어 별로 서로 다른 데이터를 재사용해야 함을 보이기 위한 분석이다).
Background
이 논문에서는 타일링 (Tiling) 방법을 사용하여 데이터를 재사용하였다. Convolution 연산은 인풋 피처맵 (Feature Map) 데이터, 웨이트 (Weight), 아웃풋 피처맵 데이터 등 큰 데이터가 많다. 이 큰 데이터를 작은 온 칩 메모리에서 모두 저장하고 계산 할 수 없기에, 데이터의 일부를 먼저 온 칩에 올려 해당 데이터에 관련된 연산을 처리하고 다음 데이터를 처리하는 방법이다.
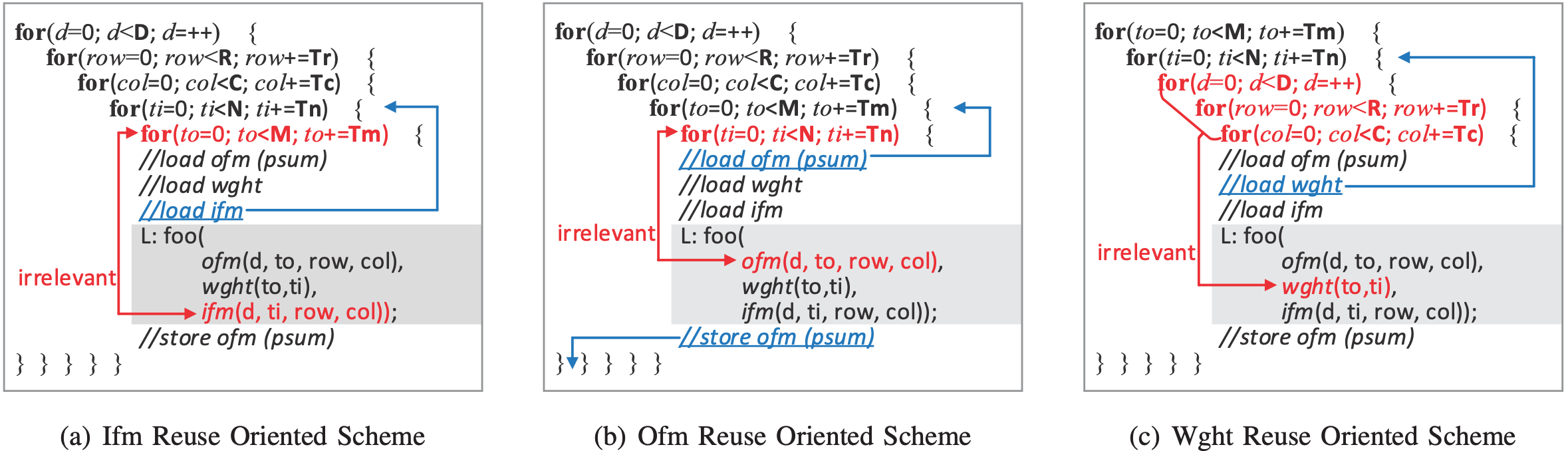
아래 그림을 보자. 바깥 for문 (흰 부분) 은 데이터를 타일 단위로 로드하기 위한 부분이고, 회색 부분의 for 문은 로드한 데이터를 계산하기 위한 부분이다. D는 배치, R/C는 아웃풋의 세로/가로, M/N은 인풋/아웃풋 피처맵을 의미한다. (자세하게 보니 글과 그림이 조금 다른 것 같다. 그림에서는 M이 아웃풋, N이 인풋 인듯…) 2번째 줄부터 4번째 줄까지 for문에서 보이듯이, 아웃풋의 세로, 가로와 인풋, 아웃풋의 채널을 타일 단위로 쪼개서 로드한 후 처리하고, 또 다음 데이터를 로드한 후 처리하는 것을 반복한다. 즉, 큰 데이터를 작은 크기의 데이터로 쪼개서 해당 데이터를 온 칩 메모리에서 오래 머물도록 하는 것 (많은 계산을 한 후 버리는 것) 이다. 아래 그림에서는 회색 부분의 계산량만큼 로드된 데이터가 온 칩 메모리에 머무르게 된다. 이 때, 계산하는 부분에 사용되는 인풋/아웃풋 피처맵과 웨이트는 모두 온 칩 메모리에 저장될 수 있어야 한다. 즉, 온 칩 메모리의 크기에 제약으로 인해 계산 부분의 계산량이 계속 커질 수는 없다.
Convolution 연산에 타일링을 적용한 수도 코드
DRAM 접근 패턴 분석
Layer Partitioning and Scheduling
위 그림에서 회색으로 표시된 계산 부분의 계산량이 커지면, 로드된 데이터를 온 칩에서 더 재사용 할 수 있어 좋다. 따라서 각 타일링 변수들을 탐색하는 것은 로드된 데이터를 얼마나 온 칩 메모리에서 재사용되느냐를 정하기 때문에 중요하다. 이뿐만 아니라, 이 논문에서는 Loop Interchange 기법을 이용하여 로드한 데이터를 더 많이 재사용한다. 아래 그림에서 보이듯이, for문들과 서로 무관한 데이터 로드를 해당 for문들 바깥으로 옮기는 것이다. 바깥으로 옮김으로써 해당 데이터는 더 많은 계산동안 온 칩 메모리에서 재사용 될 수 있다. Loop Interchange 기법은 바깥의 for문이 5개 이므로 총 5! = 120 개의 경우가 있다. 하지만 이 논문에서는 아래 그림과 같이 3가지 경우를 사용하였다.
Data Reusability and Spasity Variance
이 논문에서는 데이터 재사용과 압축률에 대한 변동성을 분석하였다. 아래 그림들과 같이 레이어마다 데이터 재사용성과 압축률이 변동이 크다. 따라서 이 논문에서 제안하는 것과 같이 레이어 별로 서로 다른 데이터 타입을 재사용하여야 한다.

SmartShuttle
위의 Layer Partitioning과 Scheduling을 탐색하는 방법에 대한 내용이다. 타일링 변수들로 표현된 오프 칩 메모리 접근량을 수식적으로 표현이 가능하므로, 수식을 세운 후 이를 푸는 방법이다. 각 과정에서 어떤 경우를 가지치고 계산하였는지에 대한 섹션이다. 아이디어 자체만을 리뷰하기 위한 글이므로 해당 부분은 생략하겠다.
실험
Manycore 형태의 NPU Eyeriss 를 사용하였으며, VGG16과 AlexNet에 대해 실험하였다.
Reference
- T. Chen, Z. Du, N. Sun, J. Wang, C. Wu, Y. Chen, and O. Temam, “Diannao: A small-footprint high-throughput accelerator for ubiquitous machine-learning,” in Proceedings of the 19th ASPLOS.
- S. Zhang, Z. Du, L. Zhang, H. Lan, S. Liu, L. Li, Q. Guo, T. Chen, and Y. Chen, “Cambricon-x: An accelerator for sparse neural networks,” in Proc. of MICRO, 2016.
- C. Zhang, P. Li, G. Sun, Y. Guan, B. Xiao, and J. Cong, “Optimizing fpga-based accelerator design for deep convolutional neural networks,” in Proceedings of the 2015 FPGA, 2015.
- M. Alwani, H. Chen, M. Ferdman, and P. Milder, “Fused-layer cnn accelerators,” in Proc. of MICRO, 2016.
comments powered by Disqus